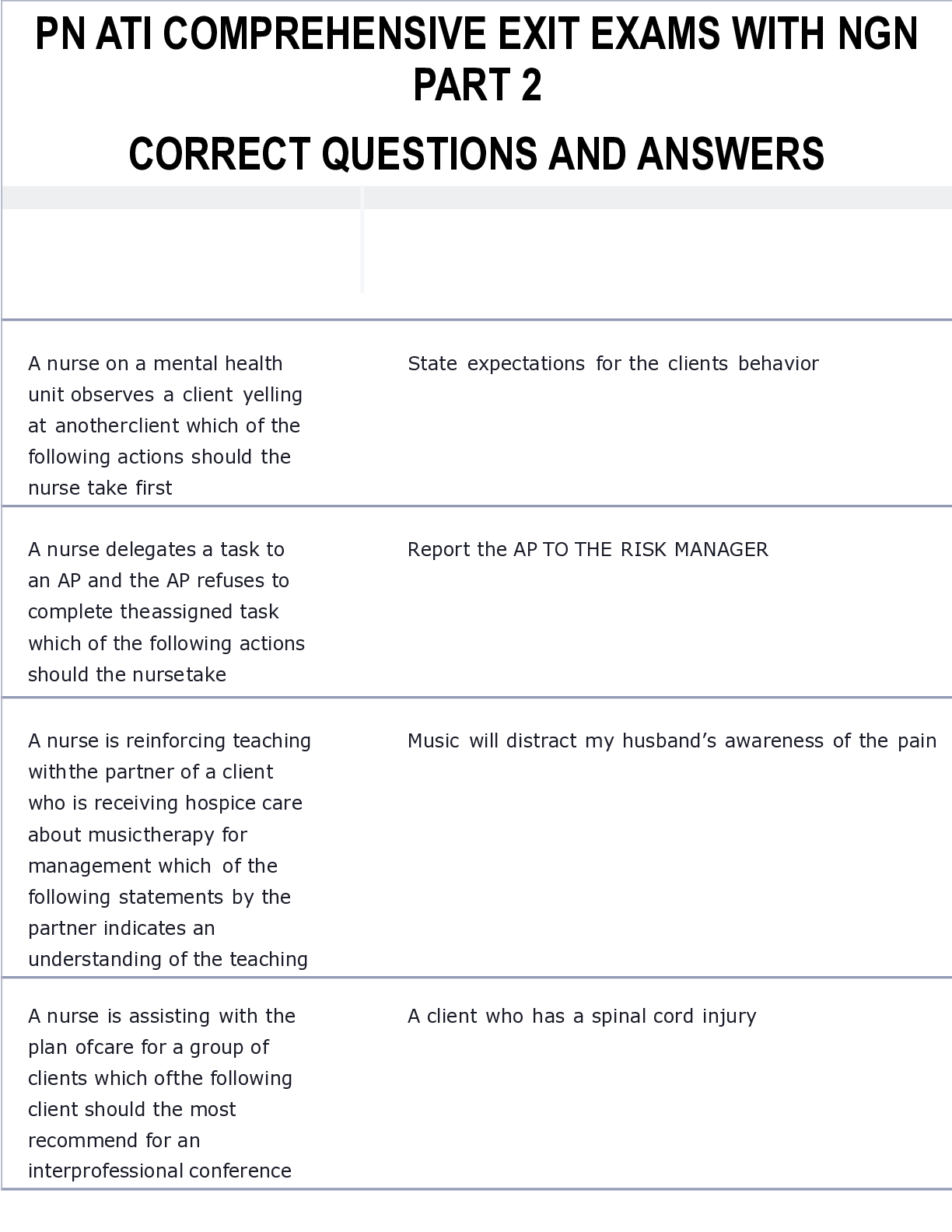
A MINI PROJECT REPORT ON
“Spam Classification Of Text
Message Dataset Using Python”
SUBMITTED TO THE SAVITRIBAI PHULE PUNE UNIVERSITY, PUNE.
FOR
LAB PRACTICE III (MACHINE LEARNING)
BACHELOR OF ENGINEERI
...
A MINI PROJECT REPORT ON
“Spam Classification Of Text
Message Dataset Using Python”
SUBMITTED TO THE SAVITRIBAI PHULE PUNE UNIVERSITY, PUNE.
FOR
LAB PRACTICE III (MACHINE LEARNING)
BACHELOR OF ENGINEERING (COMPUTER ENGINEERING)
SUBMIITED BY
Anurag Jha
B1521047
Pavan Teli
B1521052
Abhijeet Bansode
B1521046
D.Y. PATIL COLLEGE OF ENGINEERING AKURDI, PUNE- 44. SAVITRIBAI PHULE PUNE UNIVERSITY, 2020-21. DEPARTMENT OF COMPUTER ENGINEERING
Machine Learning Mini - Project
Title Mini - Project :
Classification of text Message into categories using NLP and Classification algorithm in machine learning.
Problem Definition:
Perform Data preprocessing on suitable dataset and analyze confusion matrix for different classifier models using Sci-kit learn in python. Apply the Support vector machine for classification on a dataset obtained from UCI ML repository
Prerequisite:
Knowledge of Python Programming language,
Basic Concepts of Data preprocessing (For NLP) and different techniques to build classifier model.
Software Requirements:
Python , Sklearn ,Pandas, matplotlib, numpy ,Natural language Toolkit(nltk),regular expression (re), stopwords 64 bit Operating System (Windows/Linux)
Hardware Requirement:
4GB RAM and above , 500 GB HDD and above ,
Learning Objectives:
We are going to learn how to perform data preprocessing on a dataset for cleaning the data. Build classifier models using different classification techniques like decision tree, Naive-Bayes, K-NN, Random Forest and SVM etc. and also analyze these models based on confusion matrix generated.
Outcomes:
You are able to understand Data preprocessing and confusion matrix with Python.
You are able to perform classification algorithms specifically SVM.
Theory Concepts:
Data Preprocessing :
Data preprocessing is a data mining technique which is used to transform the raw data in a useful and efficient format.
Steps involved in Data preprocessing are:
1. Data Cleaning :
The data can have many irrelevant and missing parts. To handle this part, data cleaning is done. It involves handling of missing data, noisy data etc.
(a) Missing data :
a. This situation arises when some data is missing in the data. It can be handled in various ways. Some of them are:
1. Ignore the tuples:
This approach is suitable only when the dataset we have is quite large and multiple values are missing within a tuple.
2. Fill the Missing values:
There are various ways to do this task. You can choose to fill the missing values manually, by attribute mean or the most probable value.
(b) Noisy data :
Noisy data is a meaningless data that can‘t be interpreted by machines. It can be generated due to faulty data collection, data entry errors etc. It can be handled in following ways :
1. Binning Method : This method works on sorted data in order to
smooth it. The whole data is divided into segments of equal size and then
various methods are performed to complete the task. Each segmented is
handled separately. One can replace all data in a segment by its mean or
boundary values can be used to complete the task.
2. Regression : Here data can be made smooth by fitting it to a regression
function. The regression used may be linear (having one independent
variable) or multiple (having multiple independent variables).
3. Clustering : This approach groups the similar data in a cluster.
The outliers may be undetected or it will fall outside the clusters.
2. Data Transformation:
This step is taken in order to transform the data in appropriate forms suitable for mining process. This involves following ways:
(a) Normalization : It is done in order to scale the data values in a
specified range (-1.0 to 1.0 or 0.0 to 1.0)
(b) Attribute Selection : In this strategy, new attributes are constructed from
the given set of attributes to help the mining process.
(c) Discretization : This is done to replace the raw values of numeric attribute
by interval levels or conceptual levels.
(d) Concept Hierarchy Generation : Here attributes are converted from level to higher level in hierarchy. For Example-The attribute ―city‖ can be converted to ―country‖.
2. Data Reduction :
Since data mining is a technique that is used to handle huge amount of data. While working with huge volume of data, analysis became harder in such cases. In order to get rid of this, we use data reduction techniques. It aims to increase the storage efficiency and reduce data storage and analysis costs. The various steps to data reduction are:
(a) Data Cube Aggregation : Aggregation operation is applied to data for the
construction of the data cube.
(b) Attribute Subset Selection : The highly relevant attributes should be used,
rest all can be discarded. For performing attribute selection, one can use level of
significance and p- value of the attribute. The attribute having p-value greater than
significance level can be discarded.
(c) Numerosity Reduction : This enable to store the model of data instead of
whole data, for example: Regression Models.
(d) Dimensionality Reduction : This reduce the size of data by encoding
mechanisms.It can be lossy or lossless. If after reconstruction from compressed
data, original data can be retrieved, such reduction are called lossless reduction
else it is called lossy reduction. The two effective methods of dimensionality
reduction are: Wavelet transforms and PCA (Principal Component Analysis).
Classification Models
It is a Data analysis task, i.e. the process of finding a model that describes and distinguishes data classes and concepts. Classification is the problem of identifying to which of a set of categories (subpopulations), a new observation belongs to, on the basis of a training set of data containing observations and whose categories membership is known.
Example: Before starting any Project, we need to check it‘s feasibility. In this case, a classifier is required to predict class labels such as ‗Safe‘ and ‗Risky‘ for adopting the Project and to further approve it. It is a two-step process such as:
1. Learning Step (Training Phase): Construction of Classification Model
Different Algorithms are used to build a classifier by making the model learn
using the training set available. The model has to be trained for the prediction
of accurate results.
2. Classification Step: Model used to predict class labels and testing
the constructed model on test data and hence estimate the accuracy of
the classification rules.
Classifiers can be categorized into two major types:
1. Discriminative : It is a very basic classifier and determines just one class for
each row of data. It tries to model just by depending on the observed data, depends
heavily on the quality of data rather than on distributions. Example: Logistic Regression
2. Generative : It models the distribution of individual classes and tries to learn
the model that generates the data behind the scenes by estimating assumptions and
distributions of the model. Used to predict the unseen data. Example: Naive Bayes
Classifier
Different classifier models are:
1. Decision Trees
2. Bayesian Classifiers
3. Neural Networks
4. K-Nearest Neighbour
5. Support Vector Machines
6. Logistic Regression
Support Vector Machine (SVM)
Support Vector Machine (SVM) is a supervised machine learning algorithm which can be used for both classification or regression challenges. However, it is mostly used in classification problems. In the SVM algorithm, we plot each data item as a point in n-dimensional space (where n is number of features you have) with the value of each feature being the value of a particular coordinate. Then, we perform classification by finding the hyper-plane that differentiates the two classes very well. To separate the two classes of data points, there are many possible hyperplanes that could be chosen. Our objective is to find a plane that has the maximum margin, i.e the maximum distance between data points of both classes. Maximizing the margin distance provides some reinforcement so that future data points can be classified with more confidence.
Hyperplanes are decision boundaries that help classify the data points. Data points falling on either side of the hyperplane can be attributed to different classes. Also, the dimension of the hyperplane depends upon the number of features. If the number of input features is 2, then the hyperplane is just a line. If the number of input features is 3, then the hyperplane becomes a two-dimensional plane. It becomes difficult to imagine when the number of features exceeds 3. Support vectors are data points that are closer to the hyperplane and influence the position and orientation of the hyperplane. Using these support vectors, we maximize the margin of the classifier. Deleting the support vectors will change the position of the hyperplane. These are the points that help us build our SVM.
Support Vector Machine (SVM) is a supervised machine learning algorithm capable of performing classification, regression and even outlier detection. The linear SVM classifier works by drawing a straight line between two classes. All the data points that fall on one side of the line will be labelled as one class and all the points that fall on the other side will be labeled as the second. The LSVM, that is the Linear SVM algorithm will select a line that not only separates the two classes but stays as far away from the closest samples as possible. In fact, the ―support vector‖ in ―support vector machine‖ refers to two position vectors drawn from the origin to the points which dictate the decision boundary.
The objective of SVM is to draw a line that best separates the two classes of data points.
SVM generates a line that can cleanly separate the two classes. How clean, you may ask. There are many possible ways of drawing a line that separates the two classes, however, in SVM, it is determined by the margins and the support vectors.
The margin is the area separating the two dotted green lines as shown in the image above. The more the margin the better the classes are separated. The support vectors are the data points through which each of the green lines passes through. These points are
called support vectors as they contribute to the margins and hence the classifier itself. These support vectors are simply the data points lying closest to the border of either of the classes which has a probability of being in either one.
The SVM then generates a hyperplane which has the maximum margin, in this case the black bold line that separates the two classes which is at an optimum distance between both the classes.
In case of more than 2 features and multiple dimensions, the line is replaced by a hyperplane that separates multidimensional spaces.
Natural Language processing
Natural Language Processing, or NLP for short, is broadly defined as the automatic manipulation of natural language, like speech and text, by software.
The study of natural language processing has been around for more than 50 years and grew out of the field of linguistics with the rise of computers.
Natural language refers to the way we, humans, communicate with each other. Namely, speech and text.
Mainly python developers use NLTK for natural language processing .
NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum.
Confusion Matrix:
A confusion matrix is a summary of prediction results on a classification problem. The number of correct and incorrect predictions are summarized with count values and
broken down by each class. This is the key to the confusion matrix. The confusion matrix shows the ways in which your classification model is confused when it makes predictions. It gives us insight not only into the errors being made by a classifier but more importantly the types of errors that are being made.
Class 1
Class 2
Predicted
Predicted
Class 1
TP
FN
Actual
Class 2
FP
TN
Actual
Here,
• Class 1
: Positive
• Class 2
: Negative
Definition of the Terms :
• Positive (P) : Observation is positive (for example: is an apple).
• Negative (N) : Observation is not positive (for example: is not an apple).
• True Positive (TP) : Observation is positive, and is predicted to be positive.
• False Negative (FN) : Observation is positive, but is predicted negative.
• True Negative (TN) : Observation is negative, and is predicted to be negative.
• False Positive (FP) : Observation is negative, but is predicted positive.
Accuracy : Accuracy is given by the relation -
Recall : Recall can be defined as the ratio of the total number of correctly classified positive examples divide to the total number of positive examples. High Recall indicates the class is correctly recognized (small number of FN). Recall is given by the relation –
Precision : To get the value of precision we divide the total number of correctly classified positive examples by the total number of predicted positive examples. High Precision indicates an example labeled as positive is indeed positive (small number of FP). Precision is given by the relation –






































.png)


