Information Technology > QUESTIONS & ANSWERS > ISYE 6501- Homework 1 Michael Chapman August 23, 2018, Georgia Tech, Questions with accurate answers (All)
ISYE 6501- Homework 1 Michael Chapman August 23, 2018, Georgia Tech, Questions with accurate answers
Document Content and Description Below
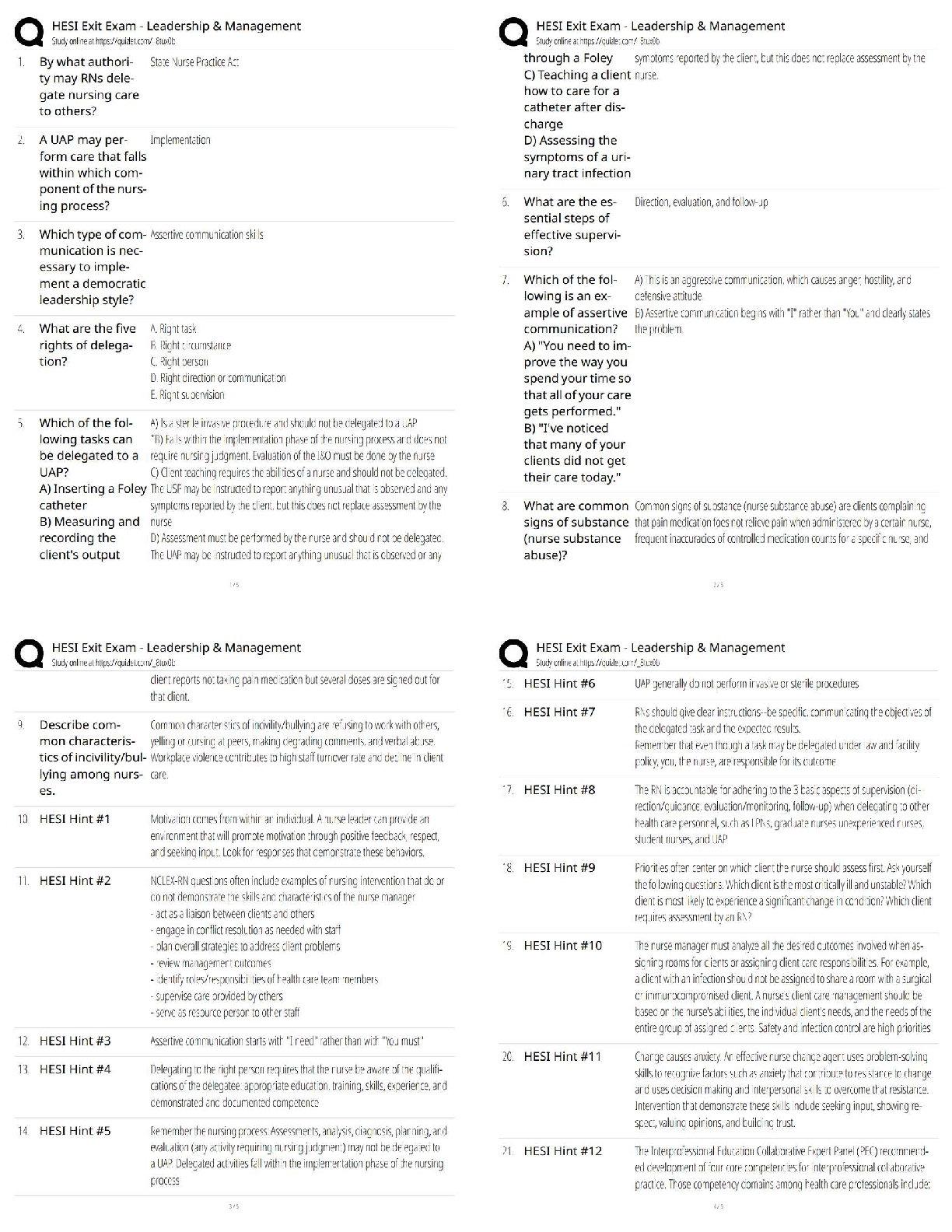
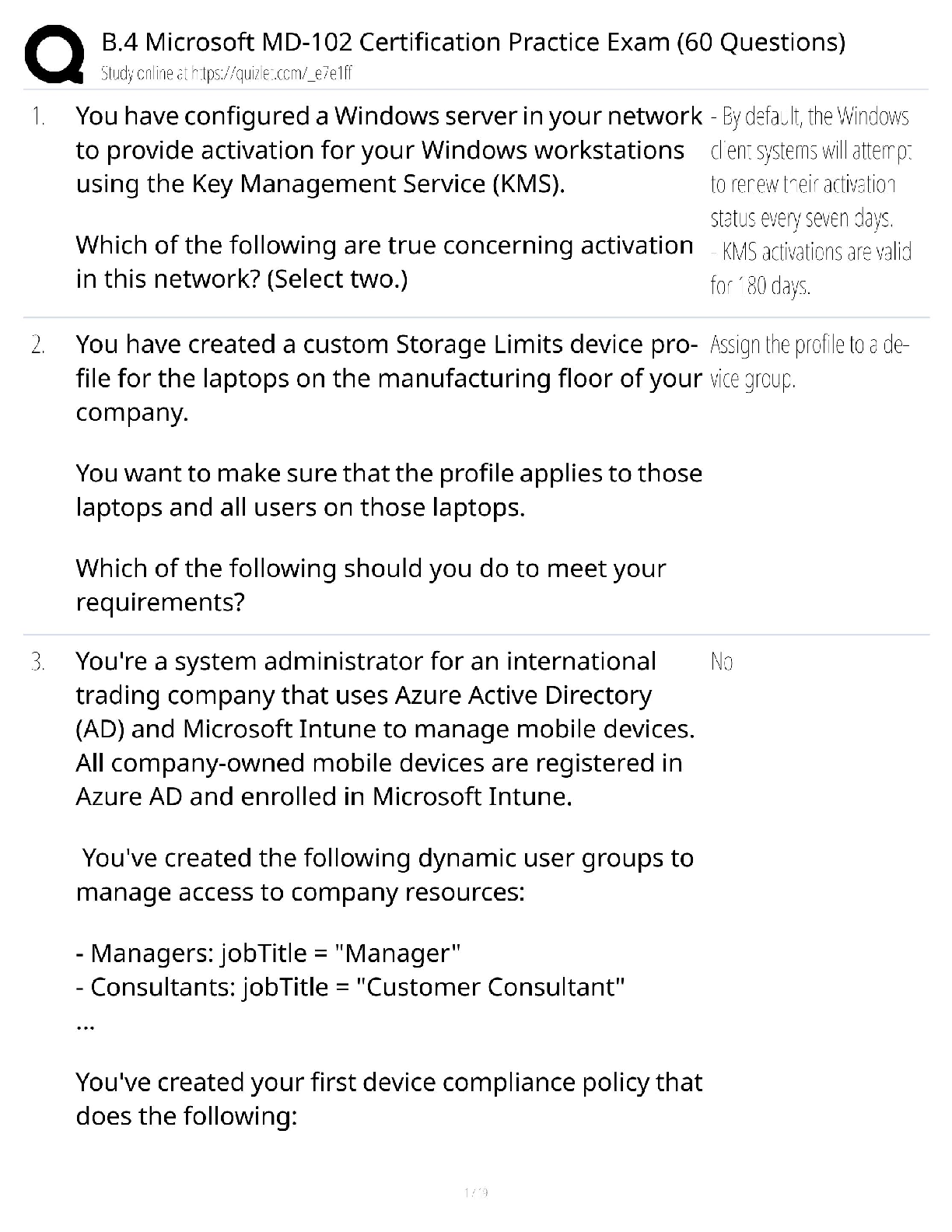
ISYE 6501- Homework 1 Michael Chapman August 23, 2018 Question 2.1 In my current job, I am responsible for understanding my company’s customer experience feedback when processing an insurance c ... laim on their mobile device. This feedback is typically in the form of a survey. The main metric we use to gauge customer satisfaction is Net Promoter Score (NPS), which is an industry standard where based on a customers response to a particular question, we put them into one of three categories: • Promoter • Neutral • Detractor One of our challenges is understanding what factor or combination of factors would result in someone being a detractor. This way we can know what to avoid things to do or try to control in order to set up a customer to not be a detractor. Using classification models, we could try to identify what individuals would be a detractor based on a number of key predictors about their claim experience. Here are a few key predictors that I might use: 1. How long it took the customer to file the claim 2. Price of the insurance deductible 3. Premium Price 4. Whether or not we required additional documentation Question 2.2 In order to find a good classifier that will properly predict the “R1” variable, I will build a Support Vector Machine (SVM) model. The goal will be to find the most accurate classifier, so I will walk through various different steps on how to prepare and assess them model, and finally arrive at our final equation. Prepare Script/Load Data First I’ll load the necessary libraries that will allow us to perform the modeling, plotting, and assessment activities. I’m assuming that the following steps are performed up front: • Dataset is in the same directory as your R script • Dataset is the “credit_card_data-headers.txt” file • For some helpful tips on managing R Projects, please see the following articles: • https://www.tidyverse.org/articles/2017/12/workflow-vs-script/ • https://support.rstudio.com/hc/en-us/articles/200526207-Using-Projects# Initial Setup ----------------------------------------------------------- # install.packages("kernlab") # Uncomment this if you don't have this installed yet # install.packages("tidyverse") # Uncomment this if you don't have this installed yet # install.packages("skimr") # Uncomment this if you don't have this installed yet # install.packages("kknn") library(tidyverse) library(kernlab) library(skimr) library(ggplot2) credit_card_file <- "credit_card_data.txt" credit_card_file_headers <- "credit_card_data-headers.txt" # If anything is using randomization, setting the seed makes this repeatable set.seed(289) # Read in the data -------------------------------------------------------- data <- read_delim(credit_card_file_headers, delim = "\t") # If you want to use the one without headers, run the below line instead # data <- read_delim(credit_card_file, delim = "\t", col_names = FALSE) Initial Data Exploration I used the package skimr to do a quick summary that shows me some quick summary statistics and a clever histogram output of each variable in the console. skim(data) I notice from here that variables A2 and A3 have the most interesting distributions. Next I’ll use some code from the dplyr library to summarize which variables are binary and which are continuous. The dplyr library is loaded automatically with the library(tidyverse) command. I highly recommend you check out https://www.tidyverse.org/ to learn more about this paradigm for data science/analytics workflows in R # Summarize Variables into Binary/Continuous ------------------------------summary_table <- data %>% gather() %>% group_by(key) %>% summarize(min = min(value), max= max(value)) %>% filter(key != "R1") %>% mutate(Variable = key, Data_Type = case_when(min == 0 & max == 1 ~ "Binary", TRUE ~ "Continuous")) %>% select(Data_Type, Variable) %>% arrange(Data_Type) knitr::kable(summary_table) Data_Type Variable Binary A1 Binary A10 Binary A12 Binary A9 Continuous A11 Continuous A14 Continuous A15 Continuous A2 Continuous A3 Continuous A8 Model Configuration Now that there is a basic understanding of the predictors/variables, I’ll start to build out the model. In order to scale this out and test difference C values (lambda) and different Kernel options, I will build a function that I can use to automate and assess various different setups. # Make a function that loops various values of C/Kernels ------------------ test_c_values <- function(c_vector, kernel_choice="vanilladot") { # Create an empty vector to store the accuracy values accuracy_vector <- vector('numeric') # Loop through the supplied c_vector parameter for(c_value in c_vector){ # Build the model for the particular c value/kernel model <- ksvm(R1~A1+A2+A3+A8+A9+A10+A11+A12+A14+A15, data = data, type="C-svc", kernel=kernel_choice, C=c_value,scaled=TRUE) # calculate a0 a0 <- -model@b # see what the model predicts pred <- predict(model,data[,1:10]) # see what fraction of the model’s predictions match the actual classification accuracy <- sum(pred == as.factor(unlist(data[,11]))) / nrow(data) # add the model's accuracy to the overall accuracy vector accuracy_vector <- c(accuracy_vector, accuracy) } # return a table of the c values/kernels and corresponding accuracy accuracy_table = tibble(C_value = c_vector, Accuracy = accuracy_vector, Kernel = kernel_choice) } Testing C Values - “vanilladot” First I will create a vector of c_values to loop through. Using this list of various different orders of magnitude, my function will build a table that contains the c value and its corresponding accuracy given the vanilladot kernel. # Run the function and check out the values ------------------------------- # Create a vector of c_values c_values <- 10^(-5:5) # Run function for vanilladot kernel accuracy_table <- test_c_values(c_values,"vanilladot") Next, I will plot out a chart that shows what accuracy each c value produces. From here I can determine which C value to chose for my final formula. # Plotting Accuracy of Different C Values --------------------------------- accuracy_table %>% ggplot(aes(x = as.factor(C_value), y=Accuracy)) + geom_col(aes(fill = Accuracy)) + xlab("C Value") + ggtitle("Accuracy of Various C (Lambda) values", subtitle = "Used in our KSVM Model: Kernel = 'vanilladot'") [Show More]
Last updated: 3 years ago
Preview 1 out of 11 pages

Buy this document to get the full access instantly
Instant Download Access after purchase
Buy NowInstant download
We Accept:

Also available in bundle (1)
Click Below to Access Bundle(s)
GEORGIA TECH BUNDLE, ALL ISYE 6501 EXAMS, HOMEWORKS, QUESTIONS AND ANSWERS, NOTES AND SUMMARIIES, ALL YOU NEED
GEORGIA TECH BUNDLE, ALL ISYE 6501 EXAMS, HOMEWORKS, QUESTIONS AND ANSWERS, NOTES AND SUMMARIIES, ALL YOU NEED
By bundleHub Solution guider 3 years ago
$60
59
Reviews( 0 )
$7.00
Can't find what you want? Try our AI powered Search
Document information
Connected school, study & course
About the document
Uploaded On
Sep 03, 2022
Number of pages
11
Written in
All
Seller

Reviews Received
Additional information
This document has been written for:
Uploaded
Sep 03, 2022
Downloads
0
Views
127