Information Technology > QUESTIONS & ANSWERS > Georgia Tech, Questions with accurate answers, Graded A+ 2022/2023 (All)
Georgia Tech, Questions with accurate answers, Graded A+ 2022/2023
Document Content and Description Below
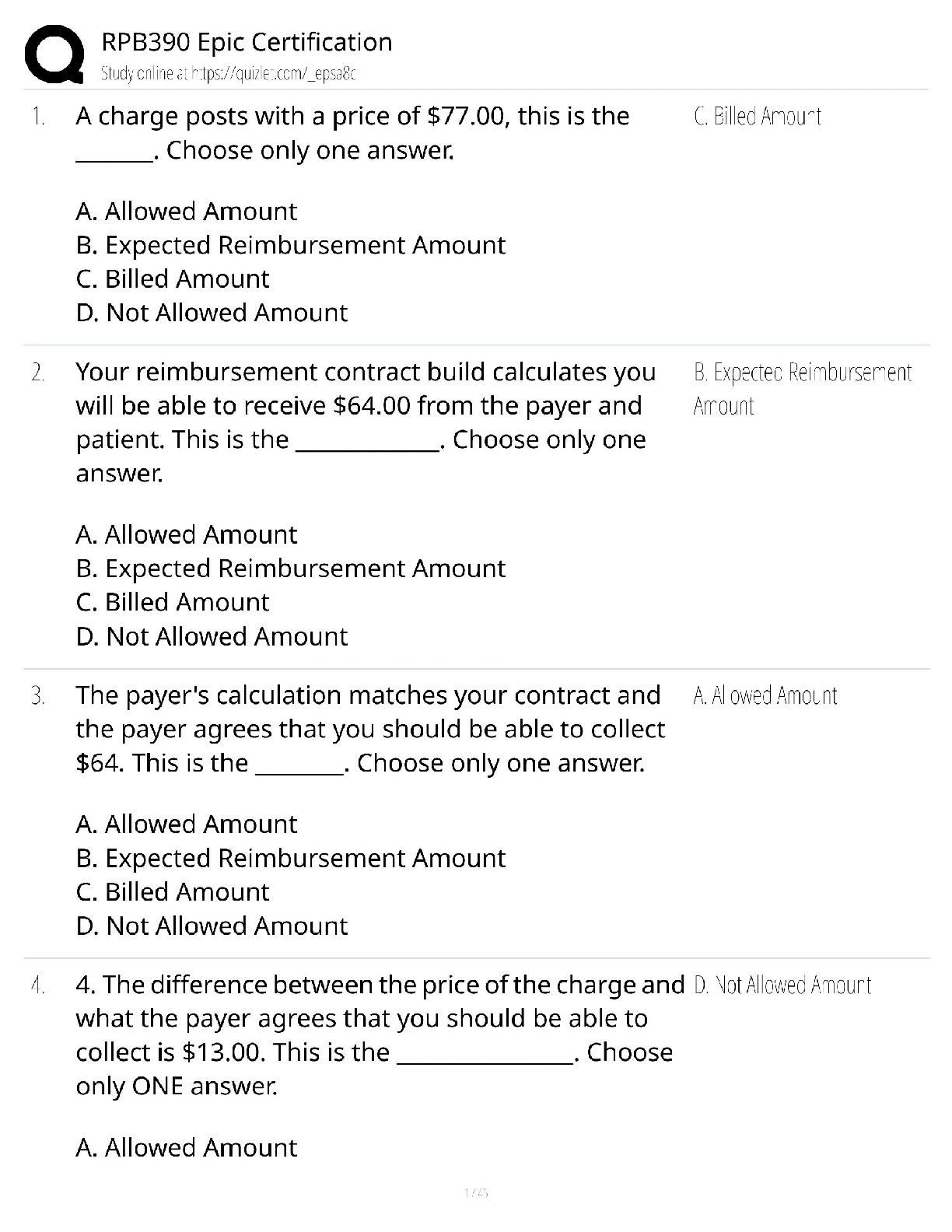
Question 8.1 Describe a situation or problem from your job, everyday life, current events, etc., for which a linear regression model would be appropriate. List some (up to 5) predictors that you mig ... ht use. Working in Canada’s biggest retail hardware store chain and building up sales analytics from the scratch, we faced a problem with gathering store transactions data due to various legal reasons. Close to 30% of our 1100+ stores across the country were initially very skeptical and reluctant on sharing their data because of a dealer-owner cooperative business model. We were receiving sales data from around 750 stores and based on which we were building dashboards and taking business decisions around various financial/merchandising/marketing goals. But we lacked the complete insight as a big chunk of data was still unknown to us. We could speculate, but it was not good enough to rely upon. At this point, we decided to build a regression model to predict what might the total sales $$ be of those ‘unknown’ stores based on criteria such as – I. Store Area (in sqrft) – expected to be a +ve correlation II. Primary LOB (hardware, building center, furniture etc.) – need to be converted to numeric values, usually stores with builder centers have larger sales $$ III. Monthly avg temp of the area code (as sales could be seasonal) – helps when we are trying to estimate monthly sales $$ for our monthly BI reports, or dealing with seasonality Question 8.2 Using crime data from http://www.statsci.org/data/general/uscrime.txt (file uscrime.txt, description at http://www.statsci.org/data/general/uscrime.html ), use regression (a useful R function is lm or glm) to predict the observed crime rate in a city with the following data: M = 14.0 So = 0 Ed = 10.0 Po1 = 12.0 Po2 = 15.5 LF = 0.640 M.F = 94.0 Pop = 150 NW = 1.1 U1 = 0.120 U2 = 3.6 Wealth = 3200 Ineq = 20.1 Prob = 0.04 Time = 39.0 Show your model (factors used and their coefficients), the software output, and the quality of fit.ISYE 6501 Week 5 HW Note that because there are only 47 data points and 15 predictors, you’ll probably notice some overfitting. We’ll see ways of dealing with this sort of problem later in the course. Ans – The uscrime dataset is has number of offences per 10k population, this is a continuous dataset with a set of possible “predictors” – #Variable Description #M percentage of males aged 14–24 in total state population #So indicator variable for a southern state #Ed mean years of schooling of the population aged 25 years or over #Po1 per capita expenditure on police protection in 1960 #Po2 per capita expenditure on police protection in 1959 #LF labor force participation rate of civilian urban males in the age-group 14-24 #M.F number of males per 100 females #Pop state population in 1960 in hundred thousand #NW percentage of nonwhites in the population #U1 unemployment rate of urban males 14–24 #U2 unemployment rate of urban males 35–39 #Wealth wealth: median value of transferable assets or family income #Ineq income inequality: percentage of families earning below half the median income #Prob probability of imprisonment: ratio of number of commitments to number of offenses #Time average time in months served by offenders in state prisons before their first release #Crime crime rate: number of offenses per 100,000 population in 1960 To understand more about the data, after loading it into a table, I looked at the data summary, looked at the box plot to check any possible outliers. Although I have not removed any data point from the set for this assignment’s purpose, I performed the test mostly for discovery, Crime values 1969 1674 1993 showed up at the highest 3 values outside the whiskers of the boxplot, using the grubbds test we possibly could remove these outliers, but I skipped this step. Later looked at the correlation matrix to check if any pair of variables are corelated to each other or not. I found that there is a strong linear correlation between Po1 and Po2 with correlation coeff = .99. Also, the Wealth and Ineq has a -ve correlation coeff -0.88 and they seem to be very closely negatively correlated. I also checked the scatter plots of predictors against Crime to have visual idea of the correlations, which showed that all of them might not be significant for out model.ISYE 6501 Week 5 HW IV. • lm – In the next step, I first used linear regression model using all the attributes in the dataset to create a baseline. The summary of this model shows only 6 attributes have a p-value < = 0.1 hence they are the only ones possibly significant enough. In real life applications with a bigger volume of data usually this threshold would be at least .05 or lower, but as we do not have enough data and 15 predictors, I am using a wider range. For this model, the R squared = 0.8031ISYE 6501 Week 5 HW Adjusted R -squared = 0.7078. The high R square shows the points are somewhat close to the trend line, but once adjusted with significant attributes, R squared goes down, which means the model explains lesser proportion of the variance in the dependent variable that is predictable from the independent variable(s) Applying model 0 our test data, we predict a value of 155.4349 ##Hypothesis Testing## - By eliminating the non-significant variables from the model 0, now the model 1 is built. The only attributes used to build this model are – M, Ed, Pol1, U2, Ineq, Prob. The Adjusted R-squared = 0.7307, which means this model can account for 73% of the outputs. Also, all the predictors remain significant based on the p value cutoffs. The R squared value in this model is lower than model0, but that is possibly because model0 had overfitting. The adjusted R square deviates from r square when we use too many predictors. Adjusted R square happens to be closer to the R square in a better model. In the case of model1 1 it the difference is 0.03, but for model0 it’s almost .1 which indicates that the Model 1 is a better.ISYE 6501 Week 5 HW The equation is – PredCrime = -5040.50 + 105.02M + 196.47Ed + 115.02Po1 + 89.37U2 + 67.65Ineq - 3801.84Prod Applying model 1 our test data, we predict a value of 1304.245 I also tested the AICs of both the models – With all the attributes AIC: 650.0291 Only with significant attributes AIC: 640.1661 ** relatively lower value of AIC indicates a better model • GLM - Similar to im, in this method, first generalized linear model has been applied with all the attributes and then based on the p value < = .1 the significant attributes have been chosen, which are - M ,Ed, Po1, U2, Ineq, Prob Applying model with all attributes on test data, we predict a value of 155.4349 Applying model with only significant attributes on test data, we predict a value of 1304.245 The equation with only significant attributes is – PredCrime = -5040.50 + 105.02M + 196.47Ed + 115.02Po1 + 89.37U2 + 67.65Ineq - 3801.84ProdISYE 6501 Week 5 HW With all the attributes AIC: 650.03 Only with significant attributes AIC: 640.17 ** The GLM models also returned the same AIC value as the LM models and the model with significant attribute would perform better than with all attributes • Cross Validation RFE method - After identifying the number of attributes from a data set through cross-validation, the recursive feature elimination keeps removing the inefficient features one by one until it reaches the optimal set of attributes as derived in the validation. By applying this method and looking at the lower Root Mean Square deviations ( translates to higher R square), the 10 significant variables are - U1, Prob , LF , Po1 , Ed , U2 , Po2 , M , Ineq , So. The equation is – PredCrime = -5099.78 - 2925.15U1 - 4000.57Prob + 531.84LF + 177.49Po1 + 210.85Ed + 150.25U2-79.51Po2 + 100.88M + 58.80Ineq + 78.48So The predicted Crime rate from test data = 870.68 R Code – rm(list = ls()) library(ggplot2) #library(tidyverse) #library(car) #Variable Description #M percentage of males aged 14-24 in total state population #So indicator variable for a southern state #Ed mean years of schooling of the population aged 25 years or over #Po1 per capita expenditure on police protection in 1960 #Po2 per capita expenditure on police protection in 1959 #LF labour force participation rate of civilian urban males in the age-g roup 14-24 #M.F number of males per 100 femalesISYE 6501 Week 5 HW #Pop state population in 1960 in hundred thousands #NW percentage of nonwhites in the population #U1 unemployment rate of urban males 14-24 #U2 unemployment rate of urban males 35-39 #Wealth wealth: median value of transferable assets or family income #Ineq income inequality: percentage of families earning below half the med ian income #Prob probability of imprisonment: ratio of number of commitments to numbe r of offenses #Time average time in months served by offenders in state prisons before t heir first release #Crime crime rate: number of offenses per 100,000 population in 1960 uscrime=read.table("C:\\Users\\AmolJ\\Downloads\\Homework\\Week5\\uscrime.txt ",header=TRUE, stringsAsFactors = FALSE) head(uscrime) ## M So Ed Po1 Po2 LF M.F Pop NW U1 U2 Wealth Ineq Pr ob ## 1 15.1 1 9.1 5.8 5.6 0.510 95.0 33 30.1 0.108 4.1 3940 26.1 0.0846 02 ## 2 14.3 0 11.3 10.3 9.5 0.583 101.2 13 10.2 0.096 3.6 5570 19.4 0.0295 99 ## 3 14.2 1 8.9 4.5 4.4 0.533 96.9 18 21.9 0.094 3.3 3180 25.0 0.0834 01 ## 4 13.6 0 12.1 14.9 14.1 0.577 99.4 157 8.0 0.102 3.9 6730 16.7 0.0158 01 ## 5 14.1 0 12.1 10.9 10.1 0.591 98.5 18 3.0 0.091 2.0 5780 17.4 0.0413 99 ## 6 12.1 0 11.0 11.8 11.5 0.547 96.4 25 4.4 0.084 2.9 6890 12.6 0.0342 01 ## Time Crime ## 1 26.2011 791 ## 2 25.2999 1635 ## 3 24.3006 578 ## 4 29.9012 1969 ## 5 21.2998 1234 ## 6 20.9995 682 test_data<-data.frame(M = 14.0,So = 0,Ed = 10.0, Po1 = 12.0,Po2 = 15.5, LF = 0.640, M.F = 94.0,Pop = 150,NW = 1.1,U1 = 0.120, U2 = 3.6, Wealth = 3200,Ineq = 20.1,Prob = 0.04, Time = 39.0) summary(uscrime) ## M So Ed Po1 ## Min. :11.90 Min. :0.0000 Min. : 8.70 Min. : 4.50 ## 1st Qu.:13.00 1st Qu.:0.0000 1st Qu.: 9.75 1st Qu.: 6.25 ## Median :13.60 Median :0.0000 Median :10.80 Median : 7.80ISYE 6501 Week 5 HW ## Mean :13.86 Mean :0.3404 Mean :10.56 Mean : 8.50 ## 3rd Qu.:14.60 3rd Qu.:1.0000 3rd Qu.:11.45 3rd Qu.:10.45 ## Max. :17.70 Max. :1.0000 Max. :12.20 Max. :16.60 ## Po2 LF M.F Pop ## Min. : 4.100 Min. :0.4800 Min. : 93.40 Min. : 3.00 ## 1st Qu.: 5.850 1st Qu.:0.5305 1st Qu.: 96.45 1st Qu.: 10.00 ## Median : 7.300 Median :0.5600 Median : 97.70 Median : 25.00 ## Mean : 8.023 Mean :0.5612 Mean : 98.30 Mean : 36.62 ## 3rd Qu.: 9.700 3rd Qu.:0.5930 3rd Qu.: 99.20 3rd Qu.: 41.50 ## Max. :15.700 Max. :0.6410 Max. :107.10 Max. :168.00 ## NW U1 U2 Wealth ## Min. : 0.20 Min. :0.07000 Min. :2.000 Min. :2880 ## 1st Qu.: 2.40 1st Qu.:0.08050 1st Qu.:2.750 1st Qu.:4595 ## Median : 7.60 Median :0.09200 Median :3.400 Median :5370 ## Mean :10.11 Mean :0.09547 Mean :3.398 Mean :5254 ## 3rd Qu.:13.25 3rd Qu.:0.10400 3rd Qu.:3.850 3rd Qu.:5915 ## Max. :42.30 Max. :0.14200 Max. :5.800 Max. :6890 ## Ineq Prob Time Crime ## Min. :12.60 Min. :0.00690 Min. :12.20 Min. : 342.0 ## 1st Qu.:16.55 1st Qu.:0.03270 1st Qu.:21.60 1st Qu.: 658.5 ## Median :17.60 Median :0.04210 Median :25.80 Median : 831.0 ## Mean :19.40 Mean :0.04709 Mean :26.60 Mean : 905.1 ## 3rd Qu.:22.75 3rd Qu.:0.05445 3rd Qu.:30.45 3rd Qu.:1057.5 ## Max. :27.60 Max. :0.11980 Max. :44.00 Max. :1993.0 str(uscrime) ## 'data.frame': 47 obs. of 16 variables: ## $ M : num 15.1 14.3 14.2 13.6 14.1 12.1 12.7 13.1 15.7 14 ... ## $ So : int 1 0 1 0 0 0 1 1 1 0 ... ## $ Ed : num 9.1 11.3 8.9 12.1 12.1 11 11.1 10.9 9 11.8 ... ## $ Po1 : num 5.8 10.3 4.5 14.9 10.9 11.8 8.2 11.5 6.5 7.1 ... ## $ Po2 : num 5.6 9.5 4.4 14.1 10.1 11.5 7.9 10.9 6.2 6.8 ... ## $ LF : num 0.51 0.583 0.533 0.577 0.591 0.547 0.519 0.542 0.553 0.632 ... ## $ M.F : num 95 101.2 96.9 99.4 98.5 ... ## $ Pop : int 33 13 18 157 18 25 4 50 39 7 ... ## $ NW : num 30.1 10.2 21.9 8 3 4.4 13.9 17.9 28.6 1.5 ... ## $ U1 : num 0.108 0.096 0.094 0.102 0.091 0.084 0.097 0.079 0.081 0.1 ... ## $ U2 : num 4.1 3.6 3.3 3.9 2 2.9 3.8 3.5 2.8 2.4 ... ## $ Wealth: int 3940 5570 3180 6730 5780 6890 6200 4720 4210 5260 ... ## $ Ineq : num 26.1 19.4 25 16.7 17.4 12.6 16.8 20.6 23.9 17.4 ... ## $ Prob : num 0.0846 0.0296 0.0834 0.0158 0.0414 ... ## $ Time : num 26.2 25.3 24.3 29.9 21.3 ... ## $ Crime : int 791 1635 578 1969 1234 682 963 1555 856 705 ... set.seed(2) library("car")ISYE 6501 Week 5 HW ## Loading required package: carData cor_matrix = round(cor(uscrime[,-16]),2) cor_matrix ## M So Ed Po1 Po2 LF M.F Pop NW U1 U2 W ealth ## M 1.00 0.58 -0.53 -0.51 -0.51 -0.16 -0.03 -0.28 0.59 -0.22 -0.24 -0.67 ## So 0.58 1.00 -0.70 -0.37 -0.38 -0.51 -0.31 -0.05 0.77 -0.17 0.07 -0.64 ## Ed -0.53 -0.70 1.00 0.48 0.50 0.56 0.44 -0.02 -0.66 [Show More]
Last updated: 3 years ago
Preview 1 out of 29 pages

Buy this document to get the full access instantly
Instant Download Access after purchase
Buy NowInstant download
We Accept:

Also available in bundle (1)
Click Below to Access Bundle(s)
GEORGIA TECH BUNDLE, ALL ISYE 6501 EXAMS, HOMEWORKS, QUESTIONS AND ANSWERS, NOTES AND SUMMARIIES, ALL YOU NEED
GEORGIA TECH BUNDLE, ALL ISYE 6501 EXAMS, HOMEWORKS, QUESTIONS AND ANSWERS, NOTES AND SUMMARIIES, ALL YOU NEED
By bundleHub Solution guider 3 years ago
$60
59
Reviews( 0 )
$6.00
Can't find what you want? Try our AI powered Search
Document information
Connected school, study & course
About the document
Uploaded On
Sep 03, 2022
Number of pages
29
Written in
All
Seller

Reviews Received
Additional information
This document has been written for:
Uploaded
Sep 03, 2022
Downloads
0
Views
137