Defence Acquisition University CLG 0010 Practice Test | 100% Correct Answers
Information Technology > QUESTIONS & ANSWERS > Georgia Tech, Question 10.1, Questiosns and answers, Rated A+ 2022/2023 (All)
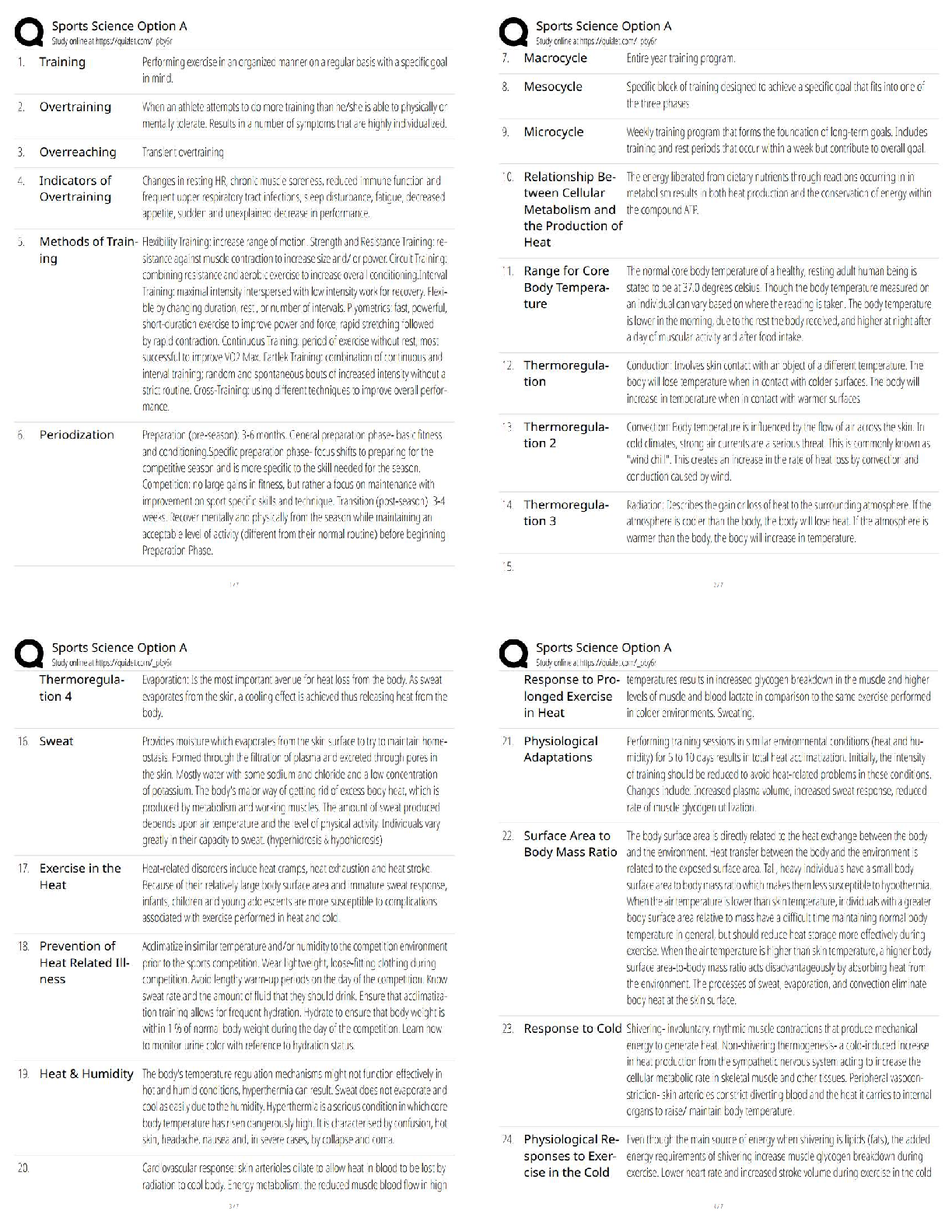
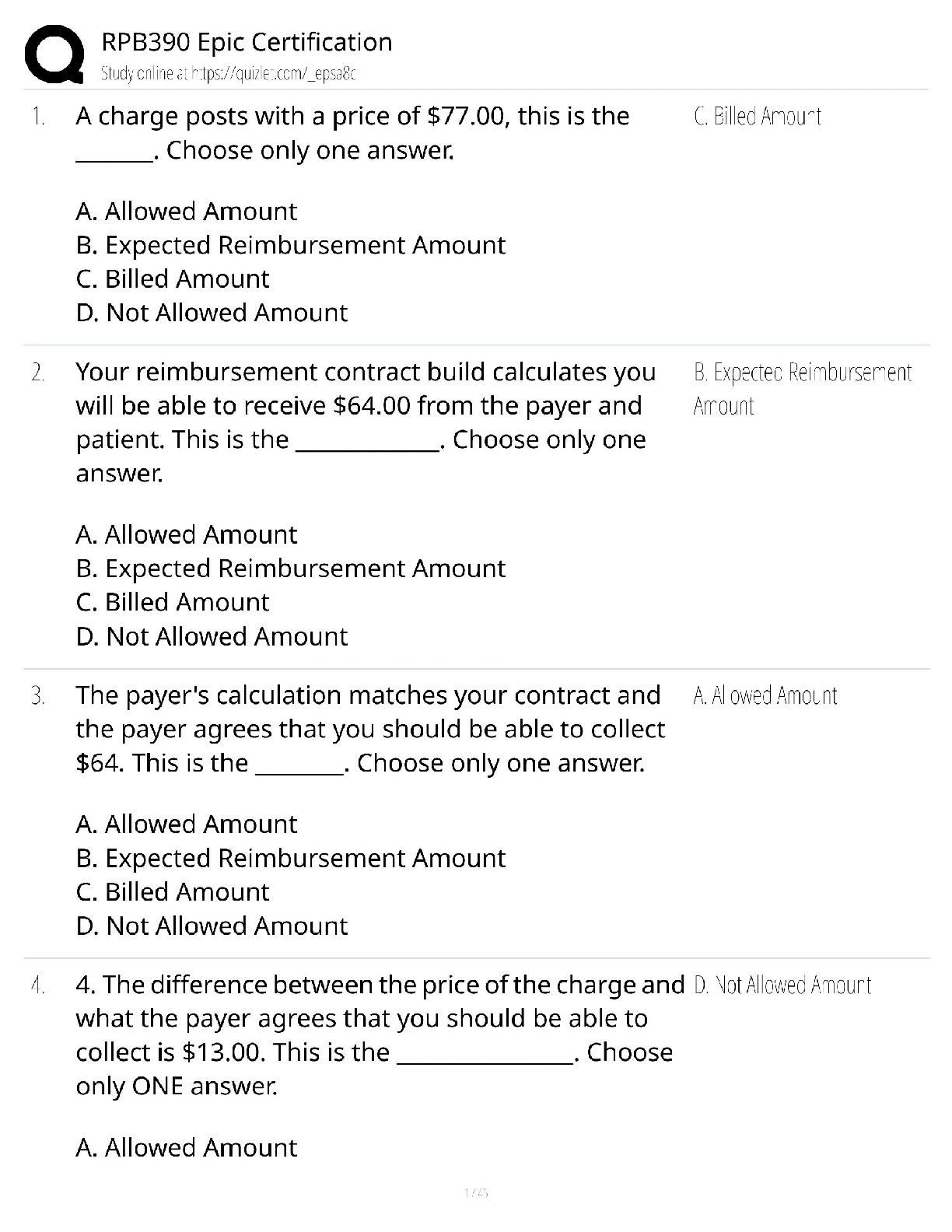
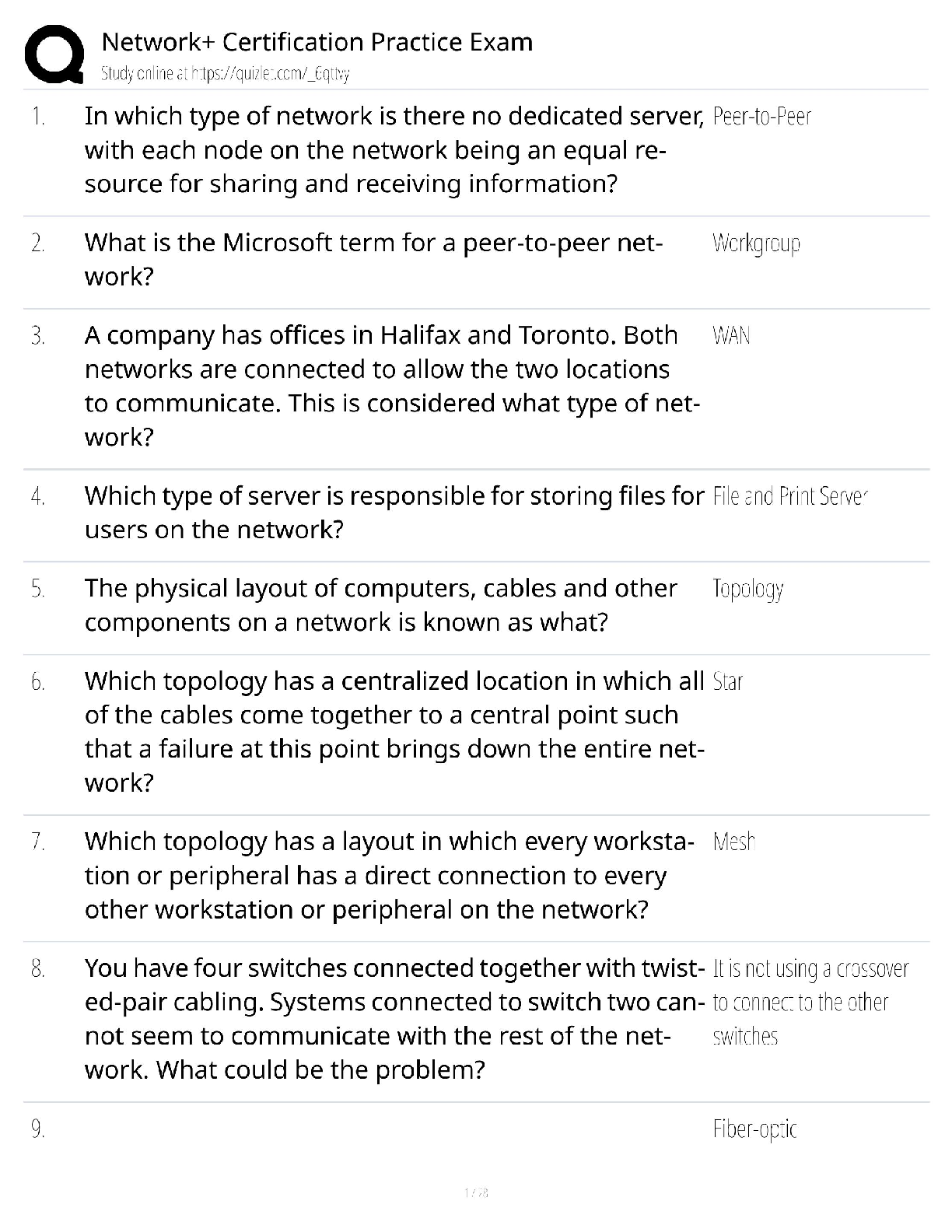
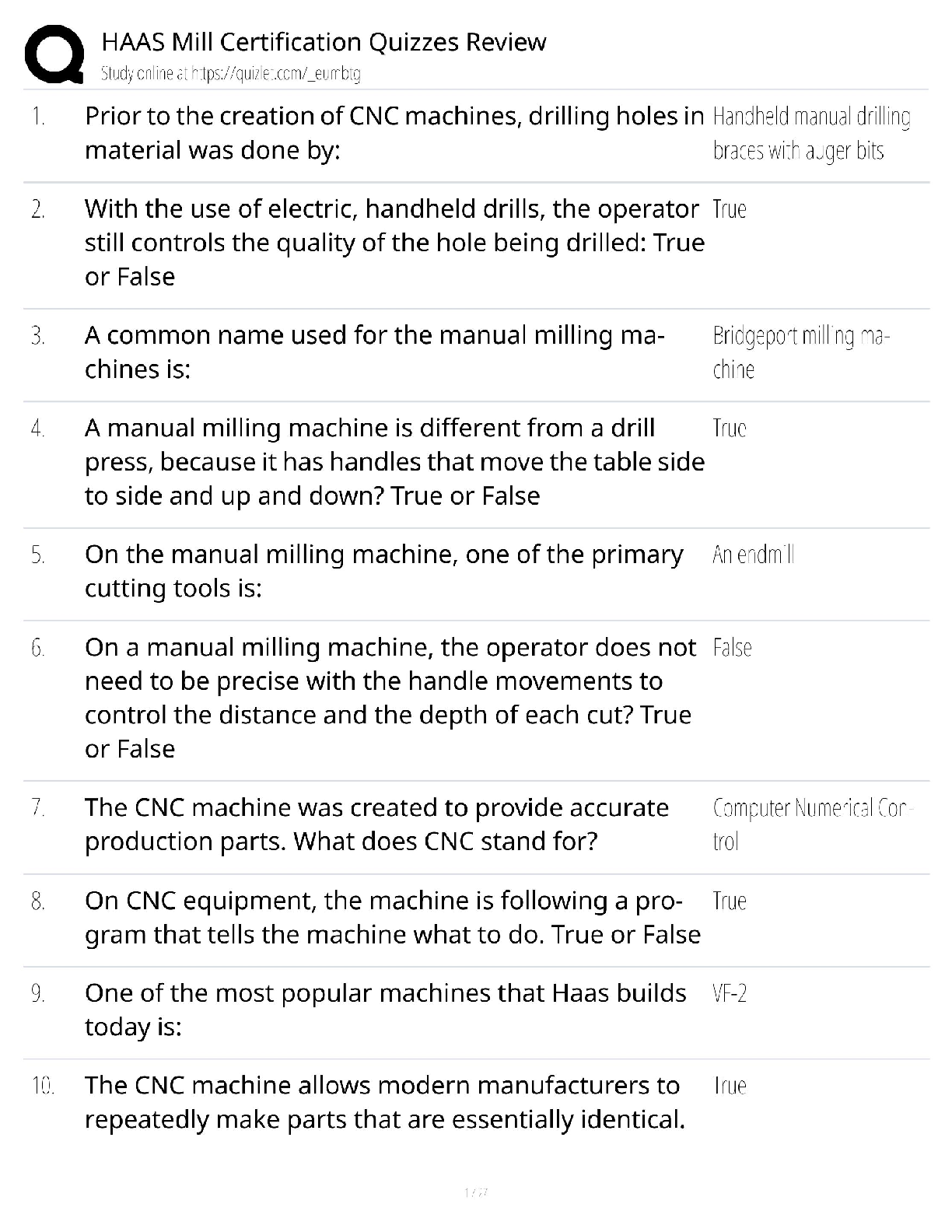
Question 10.1 Using the same crime data set uscrime.txt as in Questions 8.2 and 9.1, find the best model you can using (a) a regression tree model, and (b) a random forest model. In R, you can us ... e the tree package or the rpart package, and the randomForest package. For each model, describe one or two qualitative takeaways you get from analyzing the results (i.e., don’t just stop when you have a good model, but interpret it too). regression tree model As by now we know that the dataset contains only 47 points, for the regression tree model it might be hard to produce many splits or it might end up overfitting and we won’t be able to say for sure that the model would work as effectively with a large dataset. For this classification tree, I did not split the data in training and validation, rather used all the datapoints to create the model. The initial model used "Po1" "Pop" "LF" "NW" , the Residual mean deviance was 47390. This tree had 7 terminal nodes and looked as below – In the next step I pruned this tree with 6 , 4, 4,3 and 2 leaf nodes to look at the residual mean deviances, which kept increasing as I dropped a node. It might seem like leaf nodes = 7 is the best fit model, but because of a very small sample set this is overfitted. To solve this issue I chose to apply cross validation. cv.tree is shows a cross-validated version of the model. Instead of computing the deviance on the full training data, it uses cross-validated values for each of the 6 successive prunings. We can compare theISYE 6501 Week 7 HW deviance in the outputs of just using prune.tree with the cross validated deviance and see that the crossvalidated values are rather higher at every step. Just using prune.tree tests on the training data and so under-reports the deviance. The cv values are more realistic. My random cross validation revealed that even for leafnode = 6 the RMSE is very close to that of 7. So I chose to prune the tree with 6 leaf nodes and then calculated the R2 of both unpruned and pruned models which happened to be very close to each other, withing .72 - .7 range. If the cross validation sampling were done differently, we could get minimum RMSE for some # of leaf nodes, and similarly the regression tree model with “limited” training data may become overfitted. Takeaway – The model shows that po1 is the first variable on which the first split happens and possibly LF is least important one as in the prunes tree this gets dropped first. It also shows that NW is probably more important the Pop as in the same brunch, pruning removed Pop. But kept NW. random forest model For deciding the NodeSize and mtry of the random forest model I created a loop for node size 2 to 15 and mtry values between 1 to 10 and charted their R square values to find the optimal numbers and found that mtry=3 and NOdeSize = 3 gave the highrest R sqr = 0.4551208 I applied these values to create the model and Looked at the importance of the variables in the model.ISYE 6501 Week 7 HW Takeaway – The random forest used more number of variables as compared to the regression tree, but did not produce better R sqr values. Possibly it’s because we don’t have enough sample of data for using this method and most of the trees were very similar to each other. From the charts we can see that it seems like increased the number of variables used in ‘sampling and split’ is actually decreasing the accuracy of this model. Question 10.2 Describe a situation or problem from your job, everyday life, current events, etc., for which a logistic regression model would be appropriate. List some (up to 5) predictors that you might use. While sending out targeted emails with offers, our marketing team at a leading automotive company would do a logistic regression modelling to determine the types of email flyers offers certain groups of customers would enact to. The predictors that could be used are – Customer age group, Types od Car they own, age of car, frequency of services availed at dealership, past offer redemption types etc. Based on these customer segmentations and created and the emails are formatted accordingly through sales force. Once the recipients click through them and we get back the sales and service data from dealerships, they constitute back to the model for further adjustments. Question 10.3 1. Using the GermanCredit data set germancredit.txt from http://archive.ics.uci.edu/ml/machine-learning-databases/statlog/german / (description at http://archive.ics.uci.edu/ml/datasets/Statlog+%28German+Credit+Data%29 ), use logistic regression to find a good predictive model for whether credit applicants are good credit risks or not. Show your model (factors used and their coefficients), the software output, and the quality of fit. You can use the glm function in R. To get a logistic regression (logit) model on data where the response is either zero or one, use family=binomial(link=”logit”) in your glm function call. 2. Because the model gives a result between 0 and 1, it requires setting a threshold probability to separate between “good” and “bad” answers. In this data set, they estimate that incorrectly identifying a bad customer as good, is 5 times worse than incorrectly classifying a good customer as bad. Determine a good threshold probability based on your model. After loading the data in a table, the first thing I did is convert the output column values from 1 to 0 and 2 to 1 as the response is expected to be 0 or 1 as in yes or no. Then I split the data in 70% training and 30% validation set and created the model using the training set.ISYE 6501 Week 7 HW Looking at the logistic regression model coefficients, I picked the significant predictors with p value < = .01. As there were multiple categorical values under one column, but only few of the combinations were significant, by looking as the coefficients, I also manually removed the nonsignificant coefficients Then created another model using the significant ones from the first model. This model showed I could still remove some non-significant coefficients and by applying the same logic I came up with a model of variables V1A14, V4A41, V8, V2, V4A43, V6A65. In the next step I applied this model on my validation data after transforming it the way I did it for the training set. I created the confusion matrix by rounding up the predictions, i.e. using a threshold of .5. Observed Predicted 0 1 0 190 64 1 22 24 Although this model correctly classified a big chunk of good borrowers, but it misclassifies a lot of bad borrowers too. Now that cost of not being able to identify bad borrowers is 5 times more than not identifying good borrowers, which brings us to the idea of increasing that threshold for our classification. Hence, I tested with threshold = .7 Observed Predicted 0 1 0 209 78 1 3 10 Tested with threshold = .9 Observed Predicted 0 1 0 212 87 1 0 1 I calculated the specificity and accuracy of the model with thresholds of .5, .7 and .9 and found although the accuracy with the threshold .7 did not increase much from threshold .5, for .9 it has gone down. Whereas the specificity has gone to .98 from .89 to 1, I would prefer to stick to .7 as .9 might be very stringent and beyond this dataset, might not be a good choice with no a great model accuracy [Show More]
Last updated: 3 years ago
Preview 1 out of 44 pages

Buy this document to get the full access instantly
Instant Download Access after purchase
Buy NowInstant download
We Accept:

GEORGIA TECH BUNDLE, ALL ISYE 6501 EXAMS, HOMEWORKS, QUESTIONS AND ANSWERS, NOTES AND SUMMARIIES, ALL YOU NEED
By bundleHub Solution guider 3 years ago
$60
59
Can't find what you want? Try our AI powered Search
Connected school, study & course
About the document
Uploaded On
Sep 03, 2022
Number of pages
44
Written in
All

This document has been written for:
Uploaded
Sep 03, 2022
Downloads
0
Views
153
Scholarfriends.com Online Platform by Browsegrades Inc. 651N South Broad St, Middletown DE. United States.
We're available through e-mail, Twitter, Facebook, and live chat.
FAQ
Questions? Leave a message!
Copyright © Scholarfriends · High quality services·