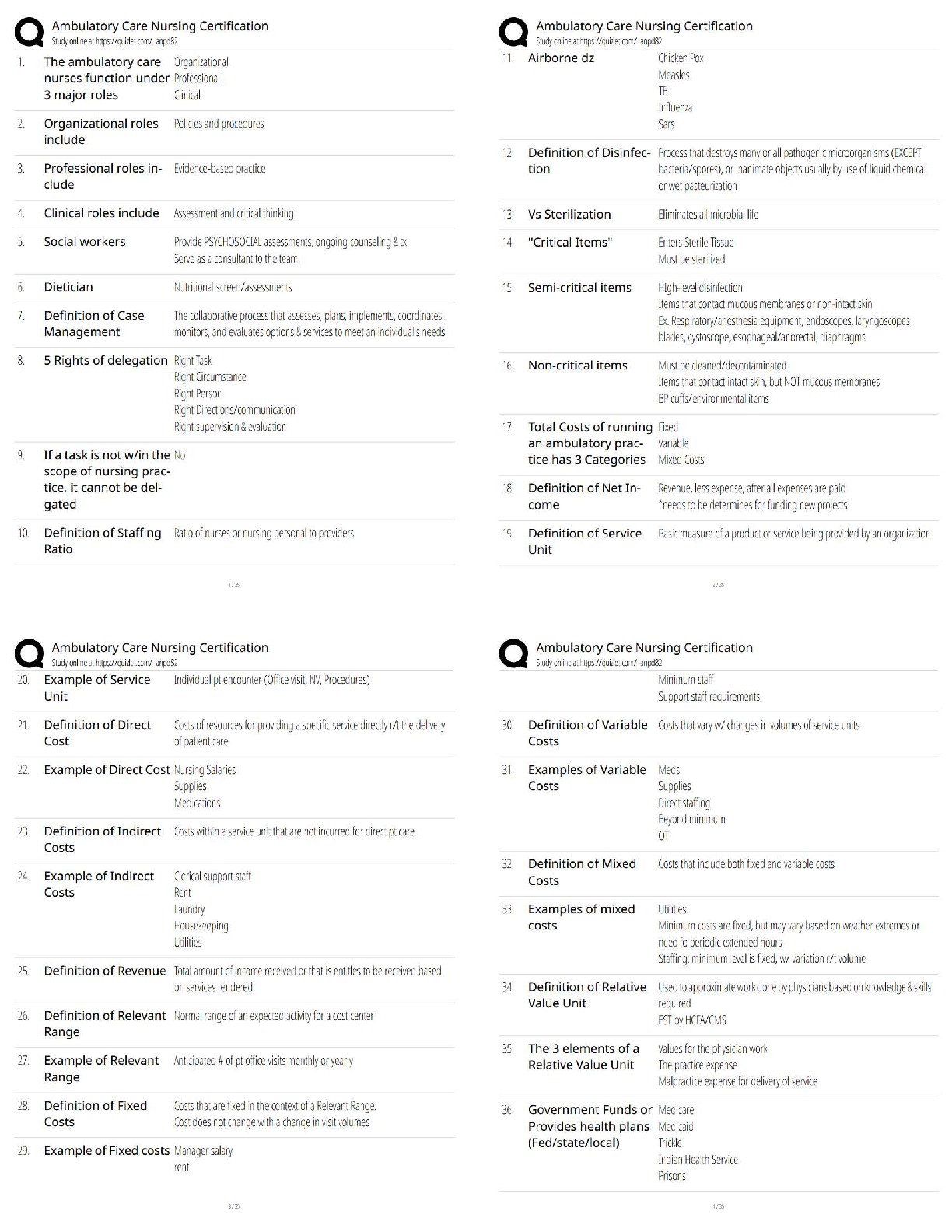
NGN NUR PSYCHIATRI Hesi-Mental-Health-Rn-v1-v3 LATEST UPDATE 2023/2024 TEST BANK RATED A+ NEW VERSIONS HESI MENTAL HEALTH RN V1-V3 2023/2024 TEST BANK.
$ 18

Engineering Economy, 8e Leland Blank, Anthony Tarquin (Solution Manual)
$ 25

HESI Pediatrics EXAM 2025 || QUESTIONS AND ANSWERS 100 % PASS SOLUTION || A+ GRADE
$ 20.5

Prioritization, Delegation and Assignment Case Study 2 with Rationale (Graded A+)
$ 9

Medical Coding & Billing Study Guide Latest Update
$ 10

Introduction to Process Control (Chemical Industries), 3rd Edition By Jose Romagnoli, Ahmet Palazoglu (CRC Press) SOLUTIONS MANUAL
$ 19
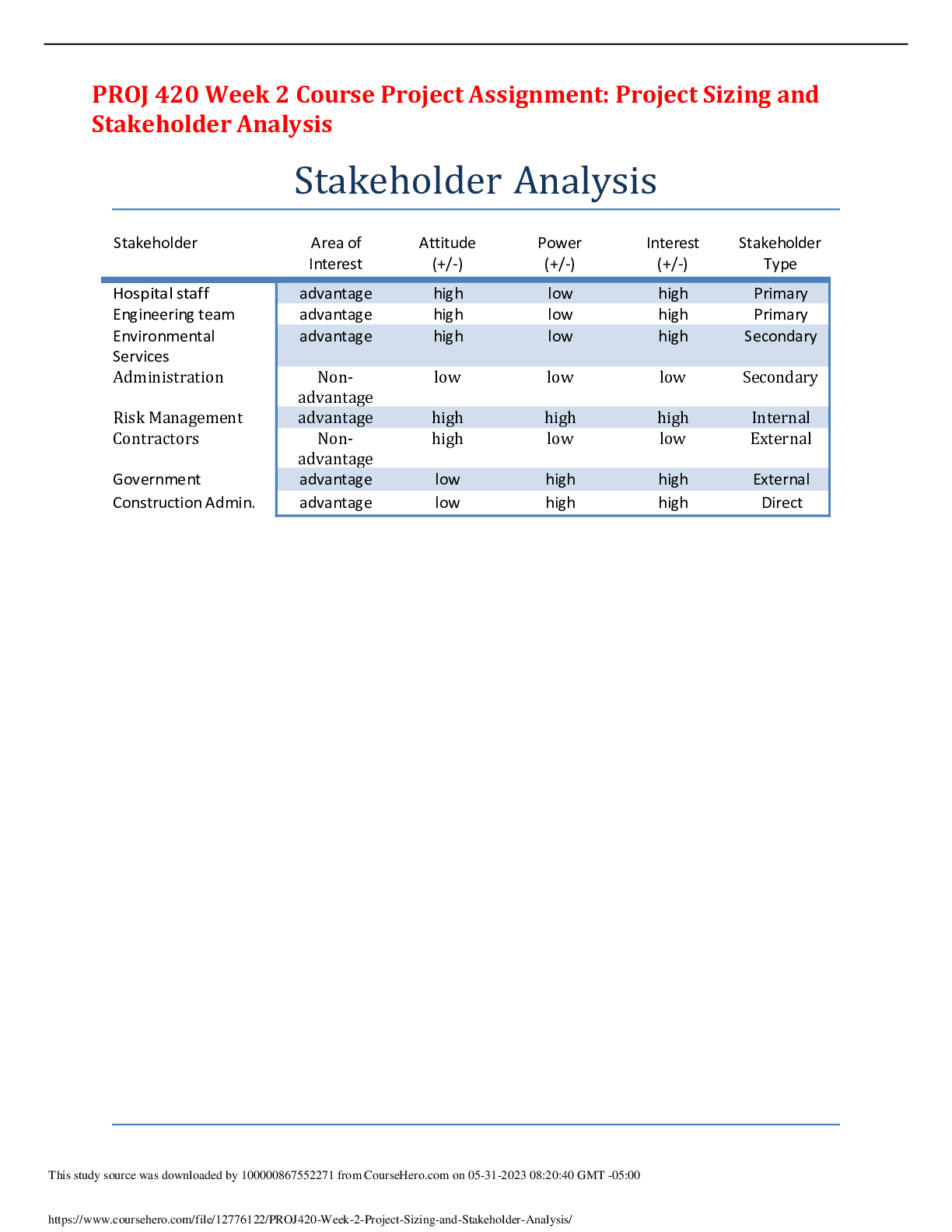
PROJ 420 Week 2 Course Project Assignment: Project Sizing and Stakeholder Analysis - Paper Graded An A
$ 8

DP600-MICROSOFT FABRIC EXAM 2026/202
$ 25

NESA EXAM QUESTIONS AND ANSWERS 100% PASS
$ 4.5
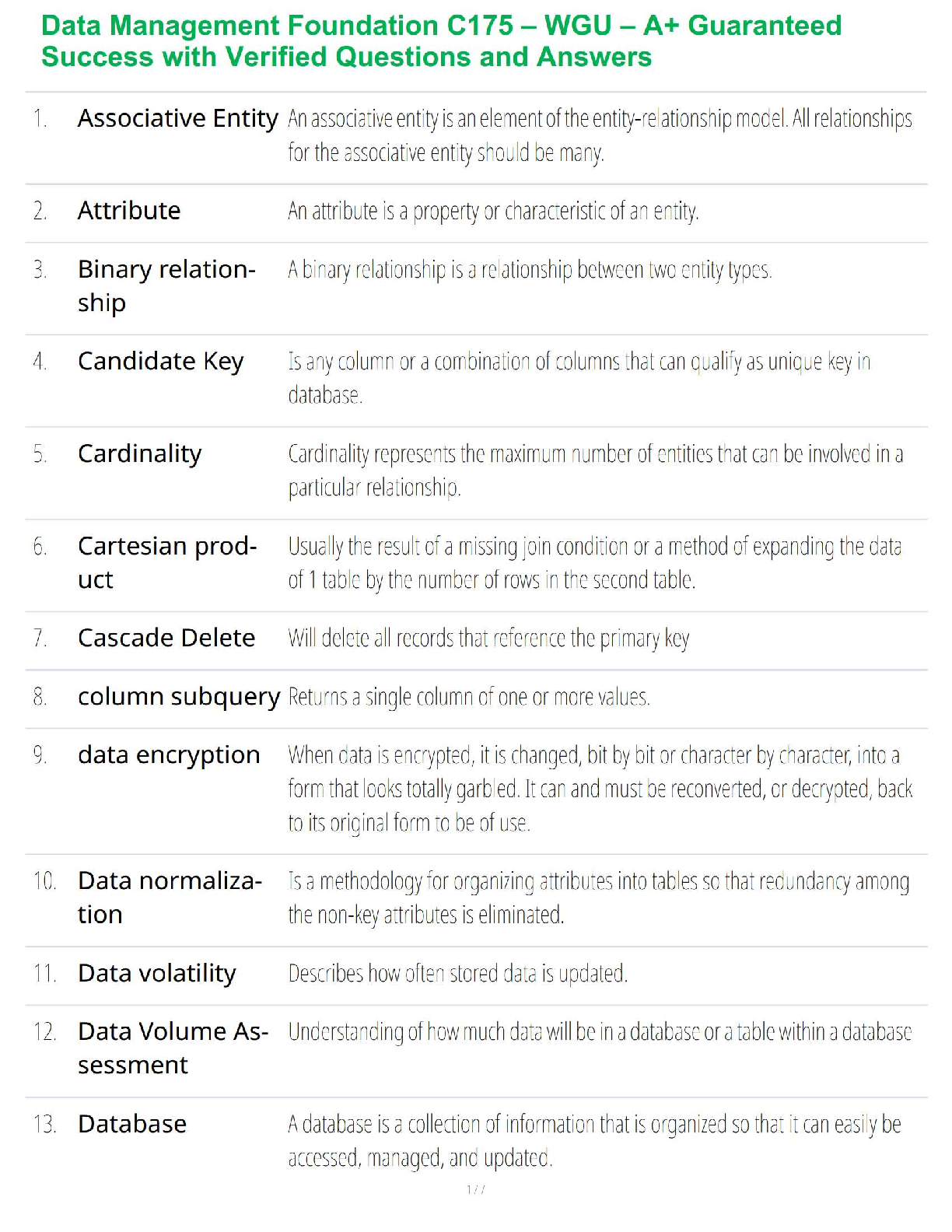
Data Management Foundation C175 – WGU – A+ Guaranteed Success with Verified Questions and Answers
$ 8.5

Fraud Examination, 5e Steve Albrecht, Chad Albrecht, Conan Albrecht, Mark Zimbleman (Test Bank)
$ 25

PHY 102-week-4-exam-solution-80-guarantee-complete-solution-guide-grand-canyon-university. LATEST FOR 2021/2022
$ 9

PHY 2048L Experiment 4 Lab Report: Force Table, Florida Atlantic University
$ 9

Solution Manual For Automotive Technology, A Systems Approach, 4th Canadian Edition by Erjavec
$ 14
.png)
WGU Humanities C100 Questions and Answers Latest Updated 2022 Already Passed
$ 15

Computer Applications Exam Study Guide.