
Regis NU641 Clinical Adv Pharmacology Final Exam 2023 LATEST UPDATE
$ 14

Zscaler EDU 200 - Essentials - ZDTA Study Set Newest 2026 Questions and Correct Detailed Answers Already Graded A+
$ 14.5
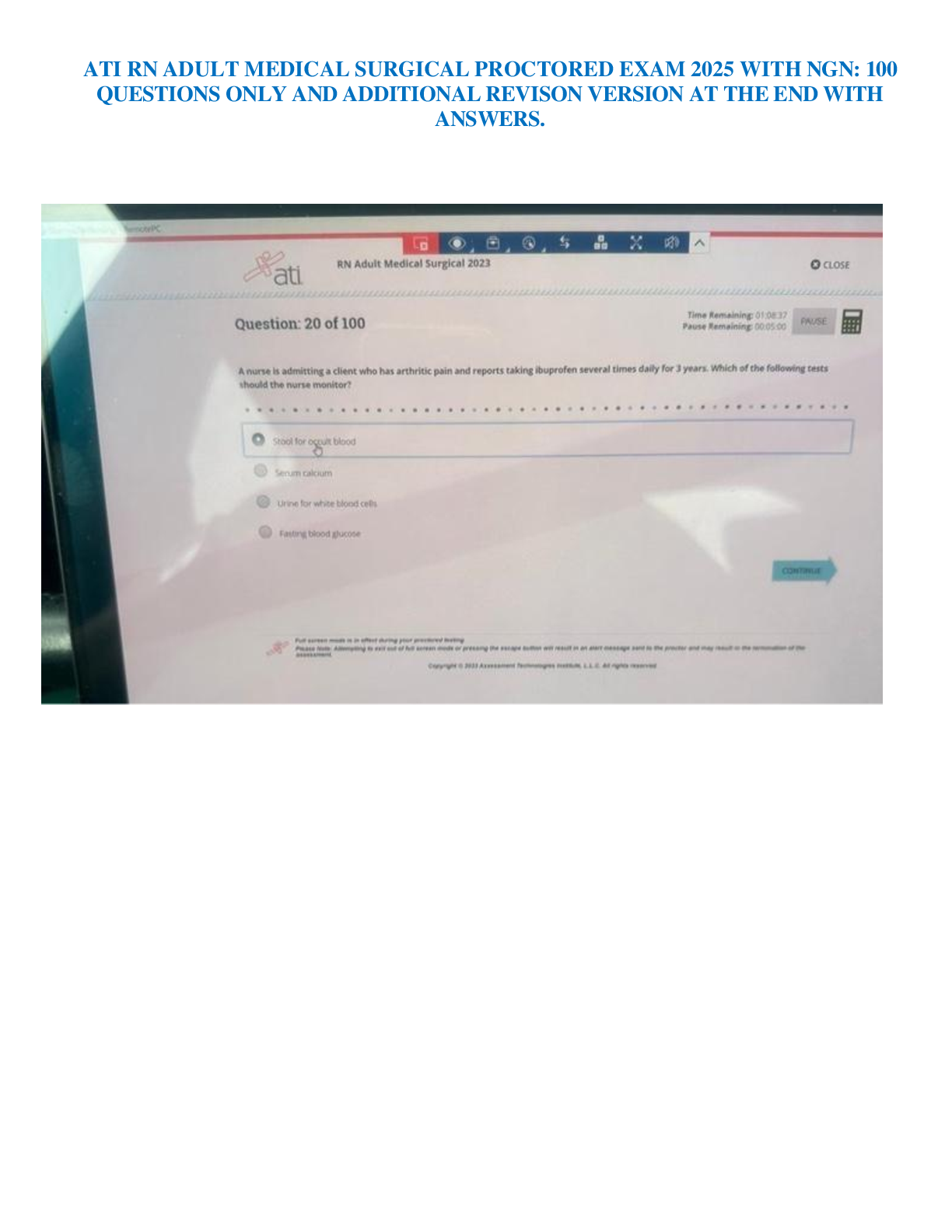
Here is the ATI RN Adult Medical Surgical (Med-Surg) Proctored Exam, featuring 100 actual exam screenshot questions with 100% verified correct answers to help you pass the RN ATI Med-Surg Proctored Exam. All exam content areas and NGN-style question formats are fully included exactly as presented in the real exam. Studying these real screenshot questions ensures full exam familiarity, accurate content coverage, and reliable preparation to pass on your first attempt.
$ 65

eBook PDF The Oxford Guide to the Uralic Languages 1st Edition By Marianne Bakró-Nagy, Johanna Laakso, Elena Skr
$ 20

[eBook] [PDF] Using AI in Marketing An Introduction BY Greg Kihlström
$ 25

Instructor Manual For Health Economics and Policy 8e James Henderson
$ 30
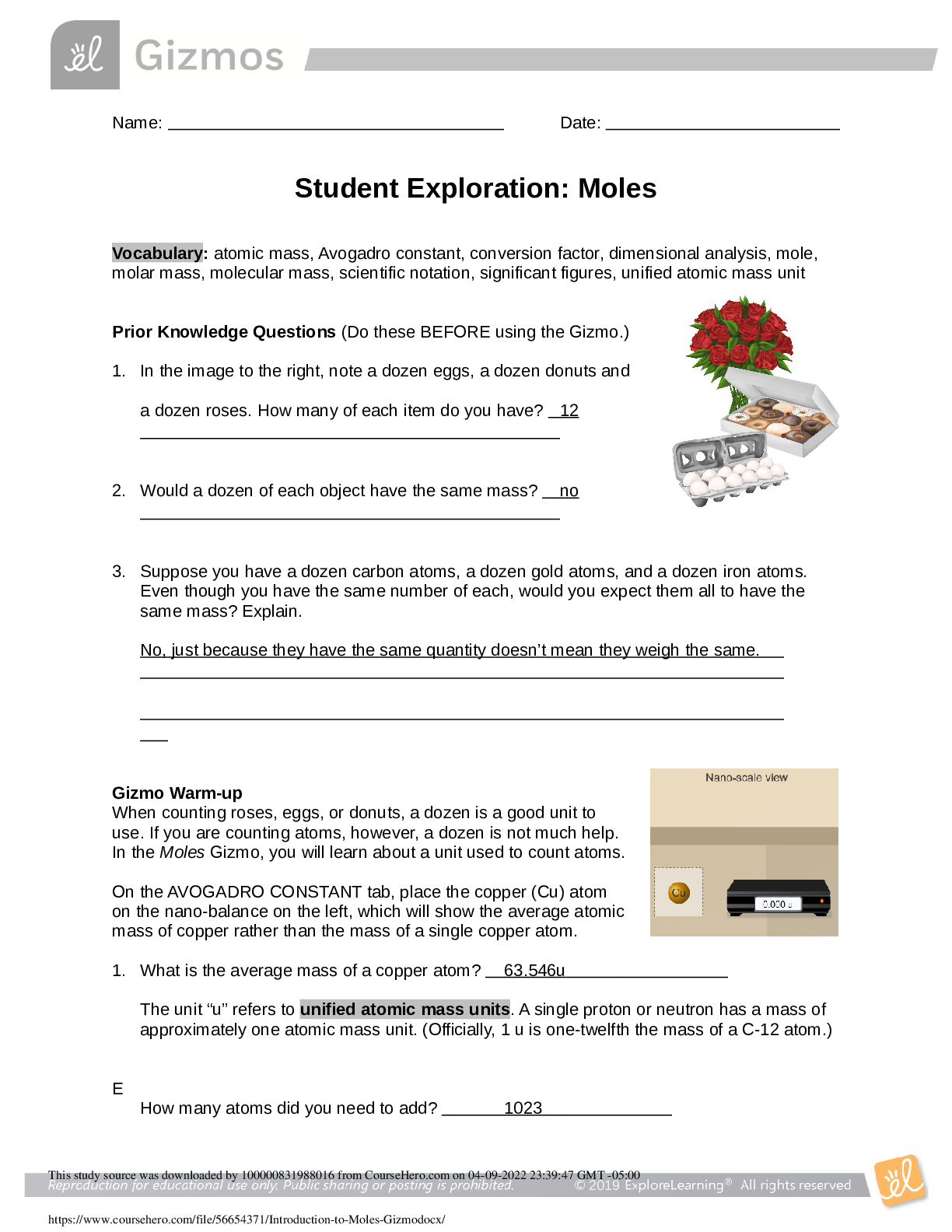
Introduction to moles Gizmos.
$ 6

eBook [EPUB] [PDF] Core Java Advanced Features Volume II (Early Release) 13th Edition By Cay Horstmann
$ 30

eBook [PDF] Principle of Macroeconomics A Streamlined Approach 4th Edition By FRANK, Bernanke, Antonovics ,Heffetz
$ 30

Anatomy & Physiology The Unity of Form and Function 9th Edition Saladin Test Bank
$ 8.5

Cyber Awareness Challenge 2022 Knowledge Check Already Passed
$ 5
Sophia Learning: US History Milestone I Questions and Answers
$ 8

Class : A Memoir of Motherhood, Hunger, and Higher Education by Stephanie Land
$ 4.5
.png)
Pearson Edexcel Level 3 GCE 8EC0/01 2022 Economics A Advanced Subsidiary PAPER 1: Introduction to Markets and Market Failure
$ 10

Henry Williams, Part 1 Guided Reflection Questions
$ 2.5

Test Bank for Pathophysiology 6th Edition by Jacquelyn Banasik
$ 28

NUR 504 Week 7 Discussion Question # 1:/FULL SOLUTION
$ 13.5

Public Relations and the Digital Professional Discourse and Change, 1st Edition By Clea Bourne [PDF] [eBook]
$ 20

Mark Scheme (Results) Summer 2022 Pearson Edexcel GCSE In Combined Science Physics (1SC0) Paper 2PF Edexcel and BTEC Qualifications
$ 8

The Beautiful and the Wild by Peggy Townsend
$ 4.5

C963 - Objective Assessment Superset Questions and Answers Graded A+
$ 8

INTERMEDIATE ACCOUNTING 1 CASH AND CASH EQUIVALENTS- Complete Notes, Defitions and Financial Calculation Guidelines
$ 6

Chamberlain College of Nursing NR439 Clarifying Research Work sheet
$ 10

NHA Medical Administrative Assistant Certification - Online Practice Tests
$ 20

Instructor Manual for Learning the Art of Helping Building Blocks and Techniques 7th Edition By Mark E. Young
$ 29

COMP 230 Week 3 Lab VBScript Network Shares Lab Report
$ 7
.png)
ENGL 216 Week 2 Course Project: Launch and Topic Proposal
$ 7.5

PEARSON BTEC Level 1/Level 2 First Award in Children’s Play, Learning and Development Unit 1: Patterns of Child Development (21468) Mark Scheme (Final) January 2022
$ 8

Answer for LDR 531 Final Exam ALL ANSWERS 100% CORRECT SPRING FALL-2022 SOLUTION GUARANTEED GRADE A+
$ 10.5

Lily Peterson_Pediatric Respiratory SIM Patient_Answered_A+ rated solution guide.
$ 9

CSE 110 Final Exam Study Guide 117 Questions with 100% Correct Answers Updated & Verified
$ 8

Homework 7 - ECE 120 - Introduction to Computing -
$ 6

AQA 7552 A Level D&T Product Design Series B - Paper 2 Designing & making principles QUESION PAPER
$ 10
 Med Surg test Latest Verified Questions and all Correct Answers with Explanations Chapter 39 Assessment of Musculoskeletal Function.png)
Sophia Milestone Adult Nursing (NUR 105) Med Surg test Latest Verified Questions and all Correct Answers with Explanations Chapter 39: Assessment of Musculoskeletal Function
$ 5

RNSG 2331 - Exam-3-capstone-1
$ 12

VIJAY RAO IHUMAN CASE STUDY: FORMAL PLAN, PATIENT ACTIVITY, DIFFERENTIAL DIAGNOSIS, HISTORY QUESTIONS AND EXPERT FEEDBACK
$ 6

ummary D182 Task 2 Professional Growth Plan.docx Running head: OHM2 Task Two: Developing a Professional Growth Plan D182 MSCIN Program, Western Governor s University D182, The Reflective Practitioner, Task 2 Introduction I am a first-grade teacher in a s
$ 10

(WGU D120) NURS 6840 SPECIAL POPULATIONS PRIMARY CARE COMPREHENSIVE FINAL OA GUIDE 2024
$ 12

Test Bank - Principles of Animal Physiology, 3rd Edition (Moyes, 2016), Chapter 1-16 All Chapters
$ 20

Instructor Manual For Psychiatric-Mental Health Nursing From Suffering to Hope 2nd Edition By Mertie Potter, Mary Moller
$ 25

Social Studies 20-1 Final Examination Study Guide
$ 12
.png)
PYC3705_Summary And Exam Notes./Best solution
$ 15.5

SAFe Certification 5.1 Exam 2024/2025/ SAFe Certification 5.1 Test (answered solution guide)
$ 14

SIT 221 Classes, Libraries and Algorithms | Import and explore the attached ISorter.cs file. It contains the ISorter interface, which consists of only a single generic method with the following signature and purpose: void Sort<K>( K[ ] array, int index, int num, IComparer<K> comparer )
$ 9

Pearson Edexcel GCE Mathematics Pure 1 Paper 9MA0/01 Mark Scheme (Results) November 2021
$ 7

eBook [ PDF] Handbook of Multisensor Data Fusion Theory and Practice 2nd Edition By Martin Liggins II, David Hall, James Llinas
$ 35

2023 GCSE Combined Science Biology A Gateway Science J250/01: Paper 1 (Foundation Tier) Question Paper & Mark Scheme (Merged)
$ 7

FFA Quiz bowl Question bank 2021-2022
$ 10

HESI MED-SURG Practice Questions And Correct Answers
$ 15
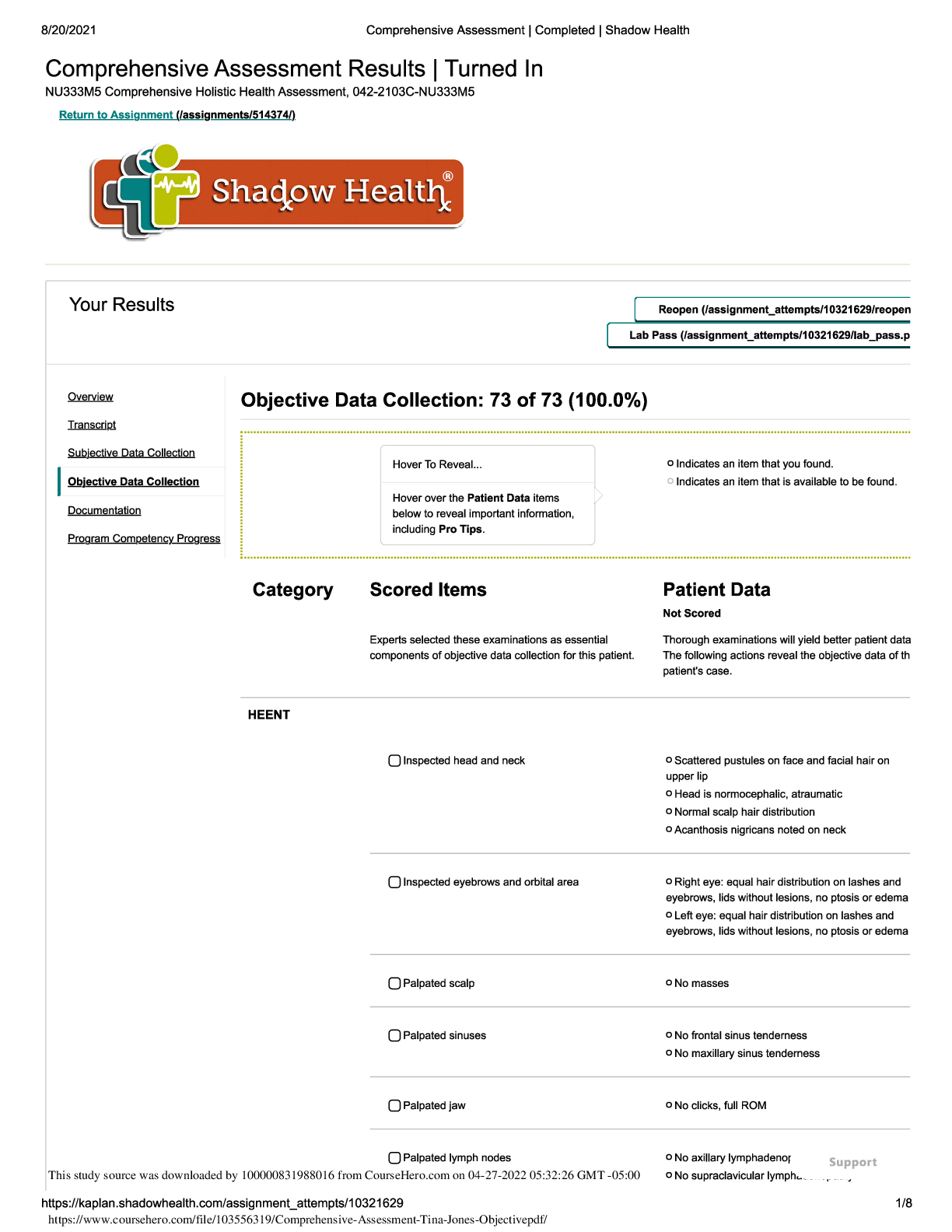
Comprehensive Assessment- Tina Jones Objective
$ 10

Nurs 251 pharmacology module 8 exam
$ 8

ISSACFT Certification Exam Questions and Answers
$ 18

GCE History A Y102/01: British period study and enquiry: Anglo-Saxon England and the Norman Conquest 1035-1107 A Level Mark Scheme for June 2023
$ 4

Environmental Science Milestone 3.docx. ALL QUESTIONS WITH ANSWERS
$ 8
Comprehensive I-human Case Study: 26-Year-Old Female with More Frequent Severe Headache
$ 37

The 5 Love Languages: The Secret to Love That Lasts
$ 4.5

2024 AQA GCSE COMBINED SCIENCE: SYNERGY 8465/4H Paper 4 Question Paper + Mark Scheme + Inserts Actual 2024 AQA GCSE COMBINED SCIENCE: SYNERGY 8465/4H Higher Tier Paper 4 Physical Sciences Merged Question Paper + Mark Scheme + Inserts
$ 7

BEST REVIEW NUR 2063 Exam 1: Essentials of Pathophysiology (Latest 2022/2023) 100% CORRECT
$ 13

Sophia Statistics Milestone 3
$ 18.5

OL Lab 7: Ideal Gas Law Learning
$ 6.5

PMHNP Certification Exam Study Guide (Comprehensive Q & A)
$ 20

Overcoming Secondary Stress in Medical and Nursing Practice: A Guide to Professional Resilience and Personal Well-Being 2nd Edition
$ 8

eBook EPUB [PDF] Civil litigation in comparative context 2nd Edition By Chase, Hershkoff, Silberman, Sorabji, Varano & Rolf Stürner & John Sorabji
$ 25

BICSI RTPM Exam Questions and Verified Answers (2025) – Graded A+ with Detailed Solutions
$ 28.5
.png)
Pearson Edexcel Level 3 GCE 8PS0/02 2022 Psychology Advanced Subsidiary PAPER 2: Biological Psychology and Learning Theories
$ 10

eBook [PDF] International Investment Law An Analysis of the Major Decisions By Hélène Ruiz Fabri Edoardo Stoppioni
$ 30
.png)
Summary Med-surg ATI practice A& B Remediation; Latest complete guide. latest 2022
$ 9.5

PHR CERTIFICATION 2023 LATEST UPDATE
$ 12.5

NR 511 NP FINAL EXAM WITH VERIFIED ANSWERS A+ GUARANTEED
$ 16

A-level PHYSICS 7408/2 Paper 2 Mark scheme June 2021 Version: 1.0 Final
$ 6.5

Psychiatric Mental Health Nursing 9th Edition questions and answers complete solution 100% 2024/2025
$ 14.5
Pass ATI PN Fundamentals Proctored Exam 2023 | 70 Full Questions with Detailed Verified Answers
$ 79

Coding > R Basics hands on The American School of Dubai DATABASE BASIC
$ 4

Level 1 Google Certification Examination Study Guide 2025
$ 10.5

OCR A LEVEL CHEMISTRY LATEST UPDATED SOLUTIONS PAPER 2 QP
$ 14
 LATEST GUIDE 2022.png)
HESI (ANATOMY AND PHYSIOLOGY) LATEST GUIDE 2022
$ 8

Nursing
$ 6

ATI PN Pharmacology Proctored Exam – Study Guide & Practice Questions
$ 40

CNA Test / Certified Nursing Assistant Exam Prep / 2025 Update / Practice Questions + Answers / Study Guide / Score 100%
$ 12

NURS 6630 week 5 Assignment: Assessing and Treating Patients With Bipolar Disorder >The patient is 26 yr. An old female of Korean descent came to her first appointment following 21 days of hospitalization for acute mania onset
$ 13.5

HESI A2 LATEST VERSION VOCABULARY LATEST FINAL EXAM UPDATED FOR 2026 ACTUAL QUESTIONS WITH 100% CERTIFIED, ELABORATED & VERIFIED SOLUTIONS TOP SCORE✓✓✓ ACE YOUR EXAMS
$ 20

BIOD 151 PORTAGE LEARNING ESSENTIAL HUMAN A & P MODULE 7 LATEST REVIEW EXAM Q & A 2024
$ 12

eBook Think Like a UX Researcher How to Observe Users, Influence Design, and Shape Business Strategy 1st Edition By David Travis, Philip Hodgson
$ 29
.png)
BUS 475 Week 9 Assignment 2 CHALLENGES IN THE BUSINESS ENVIRONMENT COMPLETE SOLUTION RATED A



























